The logit model is nonlinear in the probabilities. Whenever you have a nonlinear relationship, plots provide the most effective way of conveying it. Here, we use a plot to show how predicted probabilities change as one explanatory variable changes, holding the others constant.
A plot that shows change in an outcome as an explanatory variable changes is called a profile plot.
Introducing our example
To illustrate profile plots, we will use data on the fourth-down decisions made in all top-division (FBS) college football games over six seasons (2014-2019). If you are not familiar with American football, a team that reaches fourth down without having gained ten yards has three choices:
it can punt, giving possession to the other team;
it can attempt a field goal, to score 3 points instead of the 7 that a touchdown usually yields, or
it can go for it by trying to gain the yards they need to get a new set of downs and keep going.
Various situational factors influence whether a team decides to go for it, but an obvious one is how many yards they need to get: the fewer yards needed, the more likely to go for it. But how much more likely?
In this example:
Our outcome is a binary variable indicating whether the team goes for it.
Our key explanatory variable is the number of yards needed.
Covariates are:
How far the team is from scoring a touchdown (\(\mathtt{yds\_to\_td}\))
Whether the team is ahead, tied, or behind (\(\mathtt{score\_is}\))
What quarter it is, or whether the game is in overtime (\(\mathtt{gametime}\))
Qualitatively, these coefficients indicate that, net of one another, teams are more likely to go for it when - they need fewer yards for a first down - they need fewer yards for a touchdown - they are behind, or - it is the fourth quarter or overtime.
Mean predicted probability or predicted probability at the mean?
The clearest way to visualize how predicted probabilities change as an explanatory variable changes is to draw a plot.
But, whenever we generate predictions, those predictions depend on the values of all the explanatory variables, not just the one that we are currently focusing on. So in order to draw a graph of predicted probabilities given model estimates, we have to make a decision about the value of the other variables.
In practice, there are two main options:
Probability at the mean. Compute the predicted probability holding the other variables to their respective means. For categorical variables, this means that each level of the categorical variable will be held to its proportion in the sample.
Mean probability. Compute predicted probabilities for each of our observations, using its values for the other explanatory variables, and then take the mean of all those predicted probabilities.
These do not give the same answer–although for this purpose they are often close–and there is no blanket recommendation about which you should use.
As a practical matter using the marginaleffects package in R, once categorical variables are involved, it is easier to compute the mean probabilities because one does not have to re-fit the model with a dummy variable specification (as I showed before).
In this example, I am going to use the mean probability.
Skippable: Why did I choose to use the mean probability? For this application, talking in terms of the mean probability makes sense to me because it is easy to think about averaging over all the scenarios implied by the other covariates, while the distance to the first down varies. That is, it is easy for me to imagine that, for any of the observed situations in terms of the other covariates, teams might be facing a 4th-and-1 or a 4th-and-15, etc. in that situation.
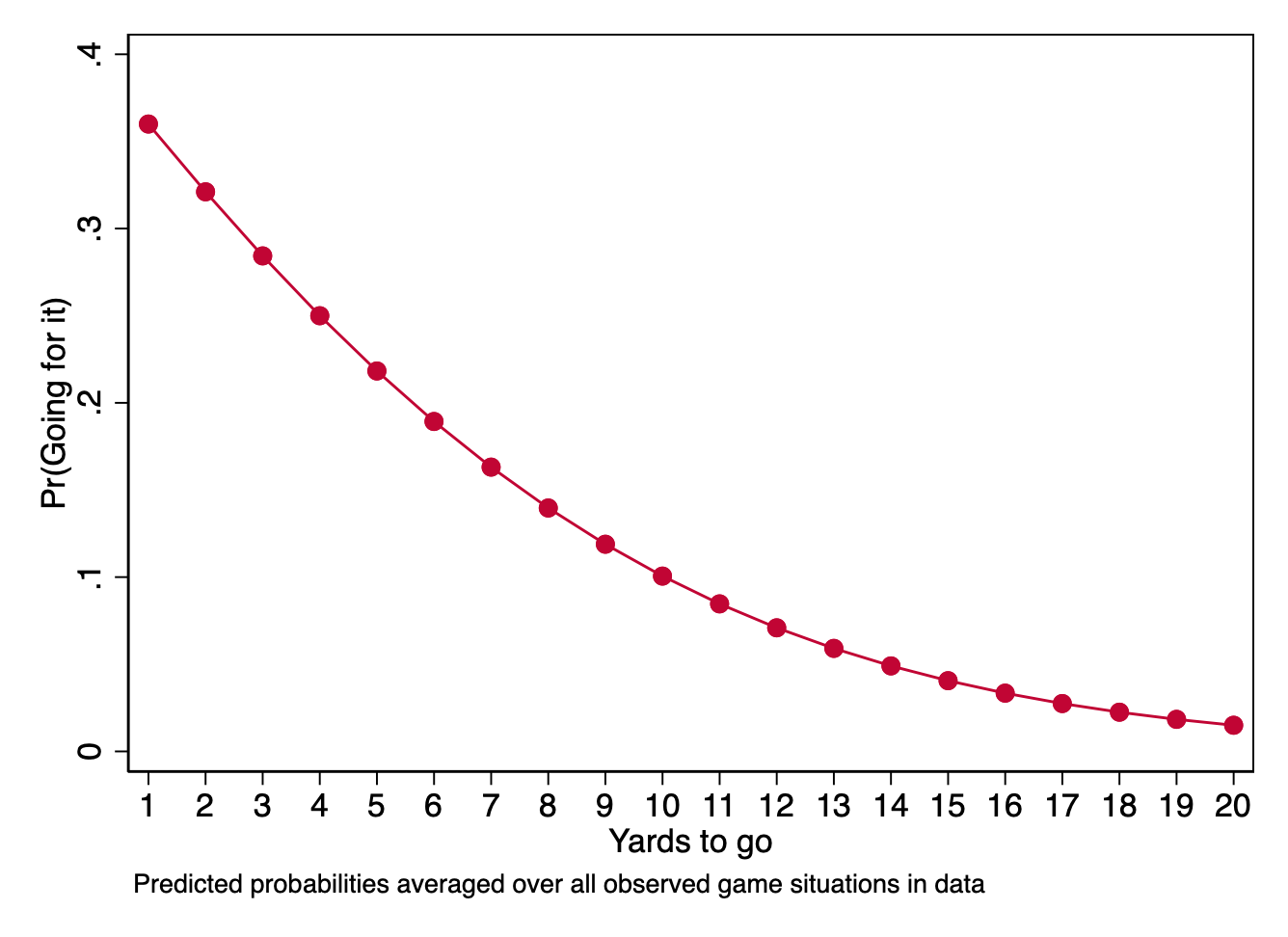
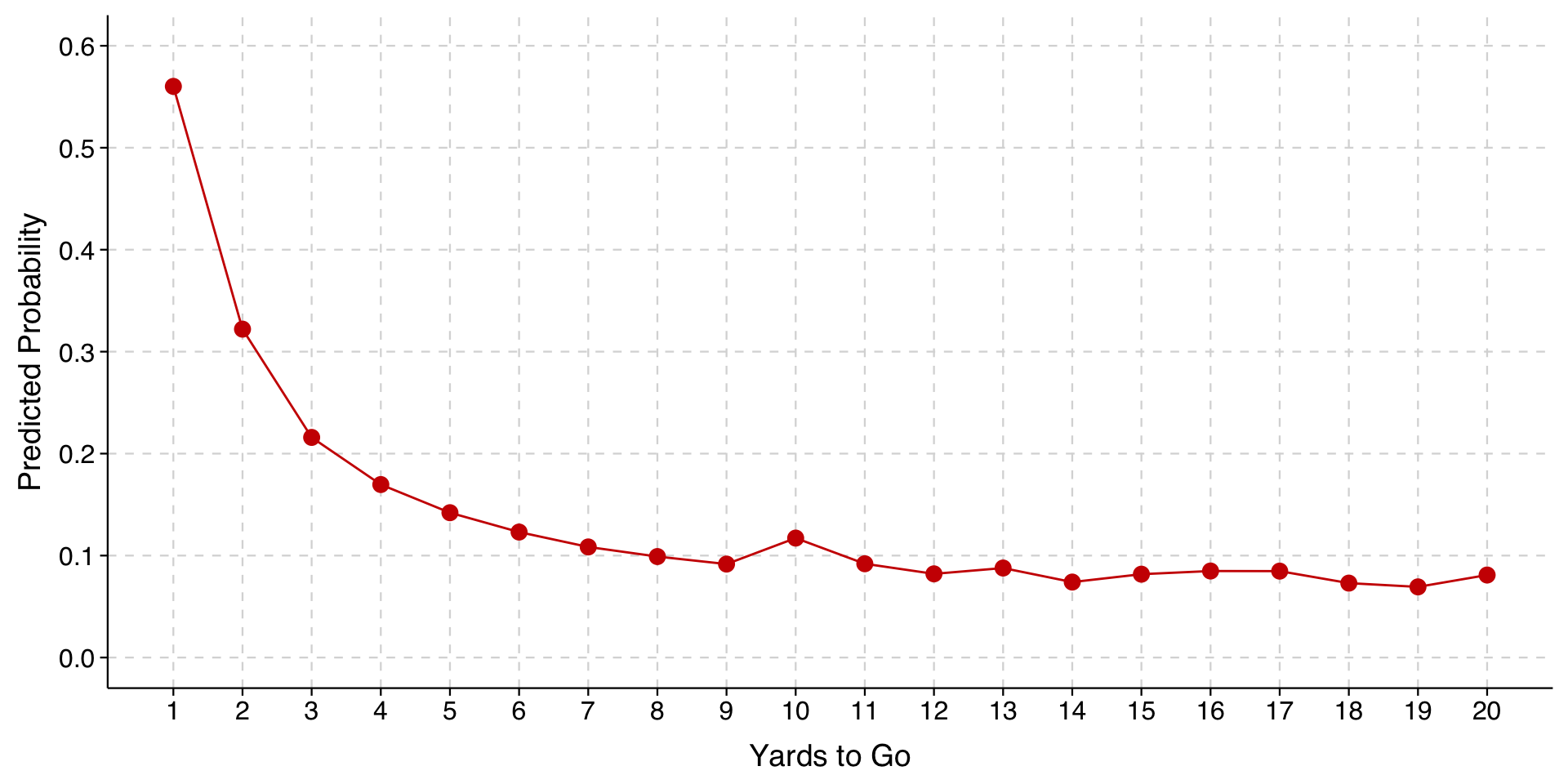
For the plot, then, we are going to compute the mean predicted probability for different values of our key explanatory variable (1-20 yards), averaging over all the observed configurations of location on the field, time in the game, and whether the team on offense is ahead or behind.
In R, we will first use the avg_predictions() from marginaleffects to generate the predictions that we want to plot. We will store these predictions in an object toplot.
\(\texttt{margins}\) is a very powerful and flexible Stata command and we will get into its intricacies only on an as needed basis. Above, we have used \(\mathtt{at()}\) to specify the values of the key explanatory variable over which we want margins to compute different predictions.
As you can see, the results are numbered. I specified the \(\mathtt{noatlegend}\) option, or else the output would have provided an \(\mathtt{\_at}\) legend indicating what each result is. But result #1 corresponds to the case in which \(\mathtt{yds\_needed}\) equals 1, and result #20 corresponds to the case in which \(\mathtt{yds\_needed}\) equals 20.
The go-to way for drawing a plot from \(\texttt{margins}\) results is to use the \(\mathtt{marginsplot}\) command.
. marginsplot, noci xtitle("Yards to go") ///
> ytitle("Pr(Going for it)") title("") ///
> plotopts(mcolor(cranberry) lcolor(cranberry)) ///
> note("Predicted probabilities averaged over all observed game situations in data")
Profile plot by levels of another explanatory variable
One idea in college and pro football is that coaches do not decide to go for it as often as they should, because it is the risky option that looks worse for them when it doesn’t work out. However, as analytics have become increasingly prominent in sports, the idea that coaches should go for it more often is well-known. So maybe coaches have come to appreciate that they have a better chance of winning by taking more risks on fourth down, or maybe not going for it has become risky in its own right now that so many journalists and fans have heard that coaches punt too much.
Either way, one might hypothesize that coaches are becoming more willing to go for it on fourth down.
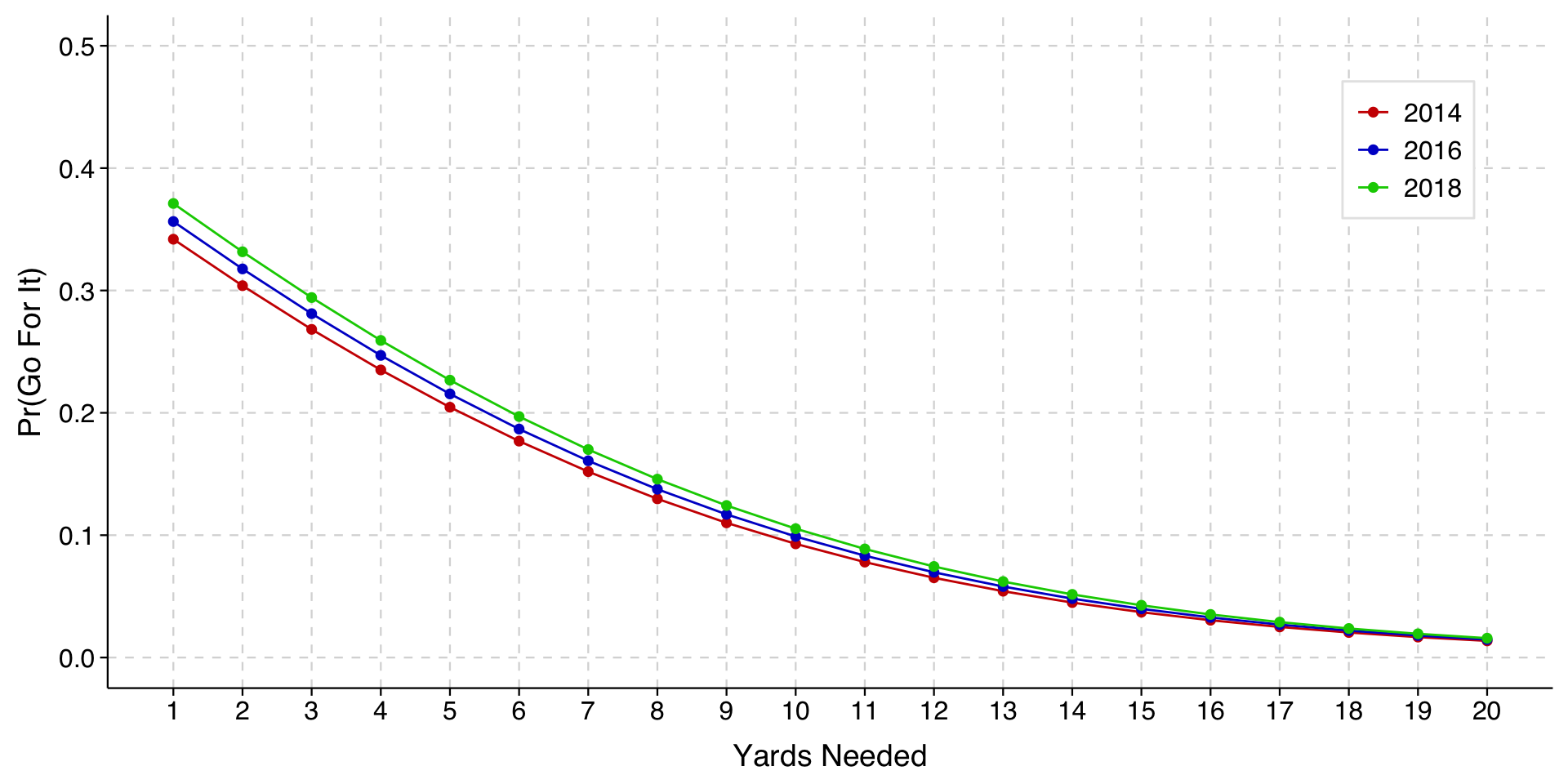
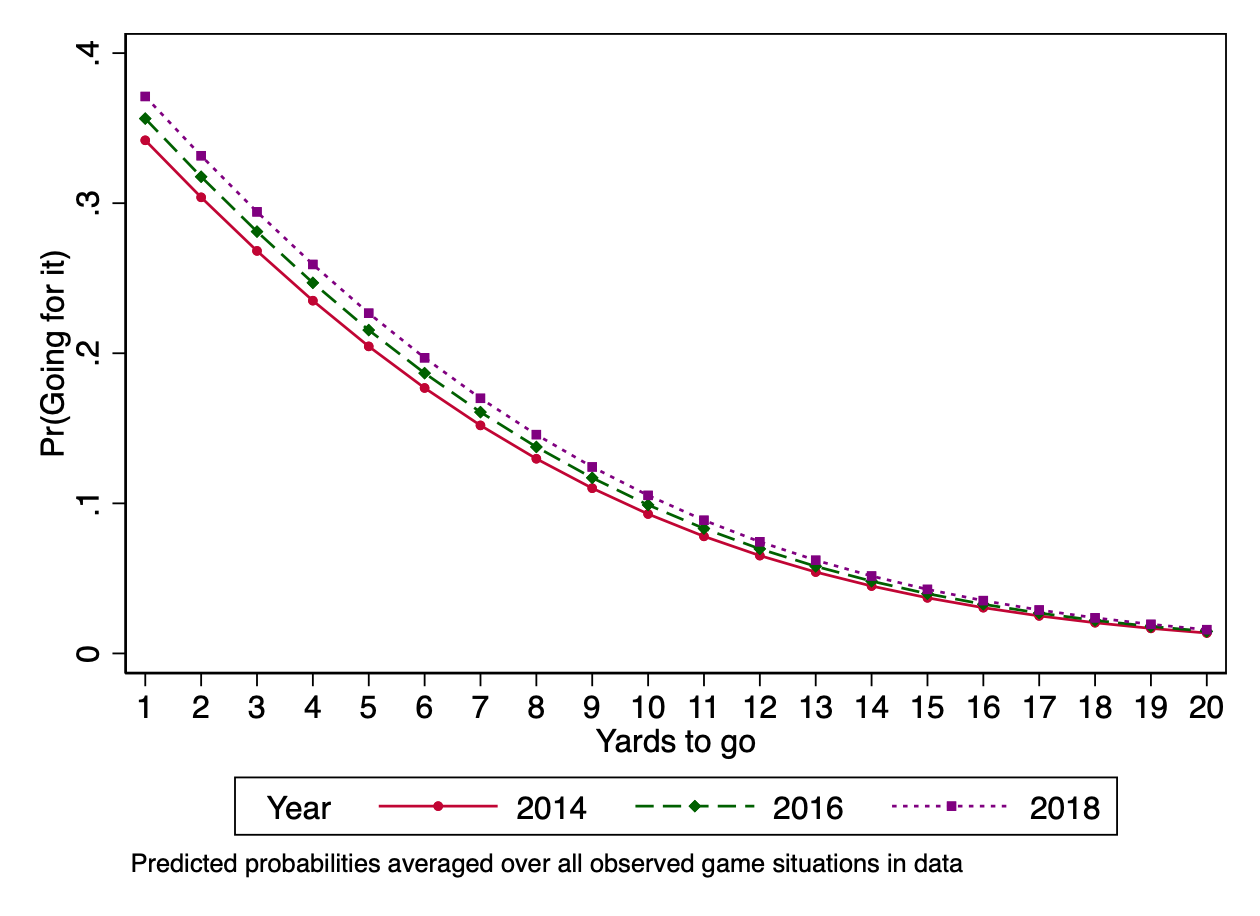
To test this hypothesis, we will add an explanatory variable for the year the game was played (year).
The highlighted result shows that teams were indeed more likely to go for it in more recent years. To visualize how much, we can draw a profile plot with different lines for different years.
Nonlinearities are not interactions
In the profile plot above, the different lines are just parallel logit curves. That is, they are the same curve just shifted to the left or right.
When we see the difference between years being larger when there are fewer yards to go, we want to recognize that this is a feature of parallel logit curves for the predicted probabilities in question. We are not saying that there is an interaction effect of yardage and year beyond this.
This is important to recognize when you see these plots in papers. Plots can show patterns that look more well-behaved than the underlying data. For example, a possible reality would be one in which coaches in recent years have become more likely to go for it on fourth down when there are few yards to go, but less likely to go for it on fourth-and-long. Such a pattern would only become visible if we include an interaction term in the model. Absent such a term, the curves will be parallel in the plot even if in reality they should not be.
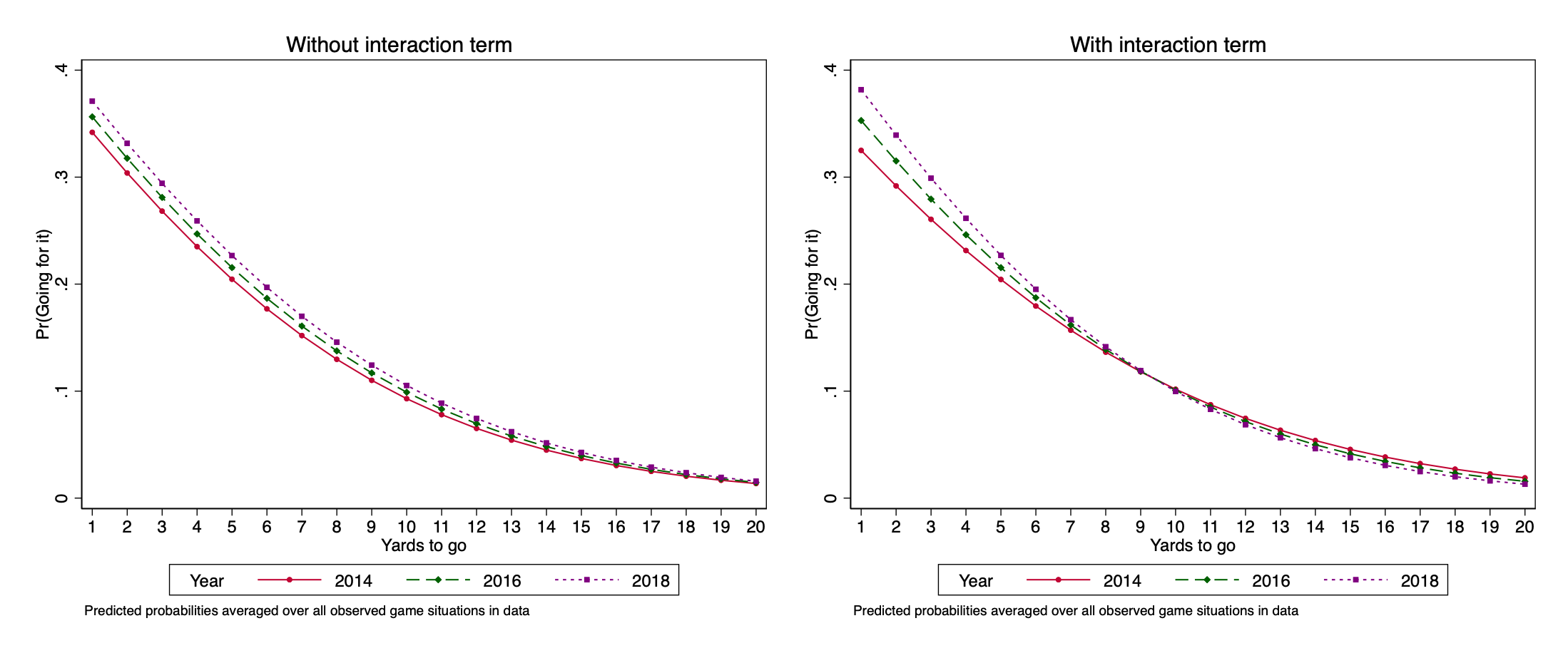
If we want to consider the possibility that these curves may not be parallel, we can model the interaction term explicitly.
When fitting interactions that involve a continuous explanatory variable, you will want either to center the variable (so that 0 = its mean) or otherwise have the variable scaled so that 0 is a meaningful value in the range of the data. We will create a variable year_min_2016 that is year - 2016, and then we will use this to fit an interaction with the yds_needed variable.
The interaction term (highlighted) is statistically significant. We can plot this interaction. We will show the plot alongside the earlier plot for the model without the interaction term so you can see the difference:
Stata note: If we use Stata’s factor variable syntax when specifying the interaction (example: \(\mathtt{c.yds\_needed\#\#c.yeartrans}\)), \(\mathtt{margins}\) and \(\mathtt{marginsplot}\) will handle the interaction properly and automatically when computing the predictions. I strongly urge you to do this when including interaction terms in your model.
The plots show that the difference over time in choices in short-yardage situations is even larger when we include the interaction term.
Aside for folks who know football: Substantively, this part makes sense. Decisions to go for it on fourth-and-long are typically matters of desperation: the main situation where teams do it is when they are behind late in the game. Analytics have had no argument with conventional coaching wisdom about that.
Instead, where analytics have called conventional coaching decisions into question is about fourth-and-short, and so it is not surprising that once we let the curves be non-parallel, we see bigger differences for shorter yardage.
Nonlinear nonlinearities
When we add the interaction term, we are still drawing regular logit curves for a continuous explanatory variable; we are just allowing the curves not to be parallel. That is, we are still assuming that the relationship between distance and fourth-down-decision is linear in the logit, even though with the interaction terms we are allowing the slope of that relationship to differ by year.
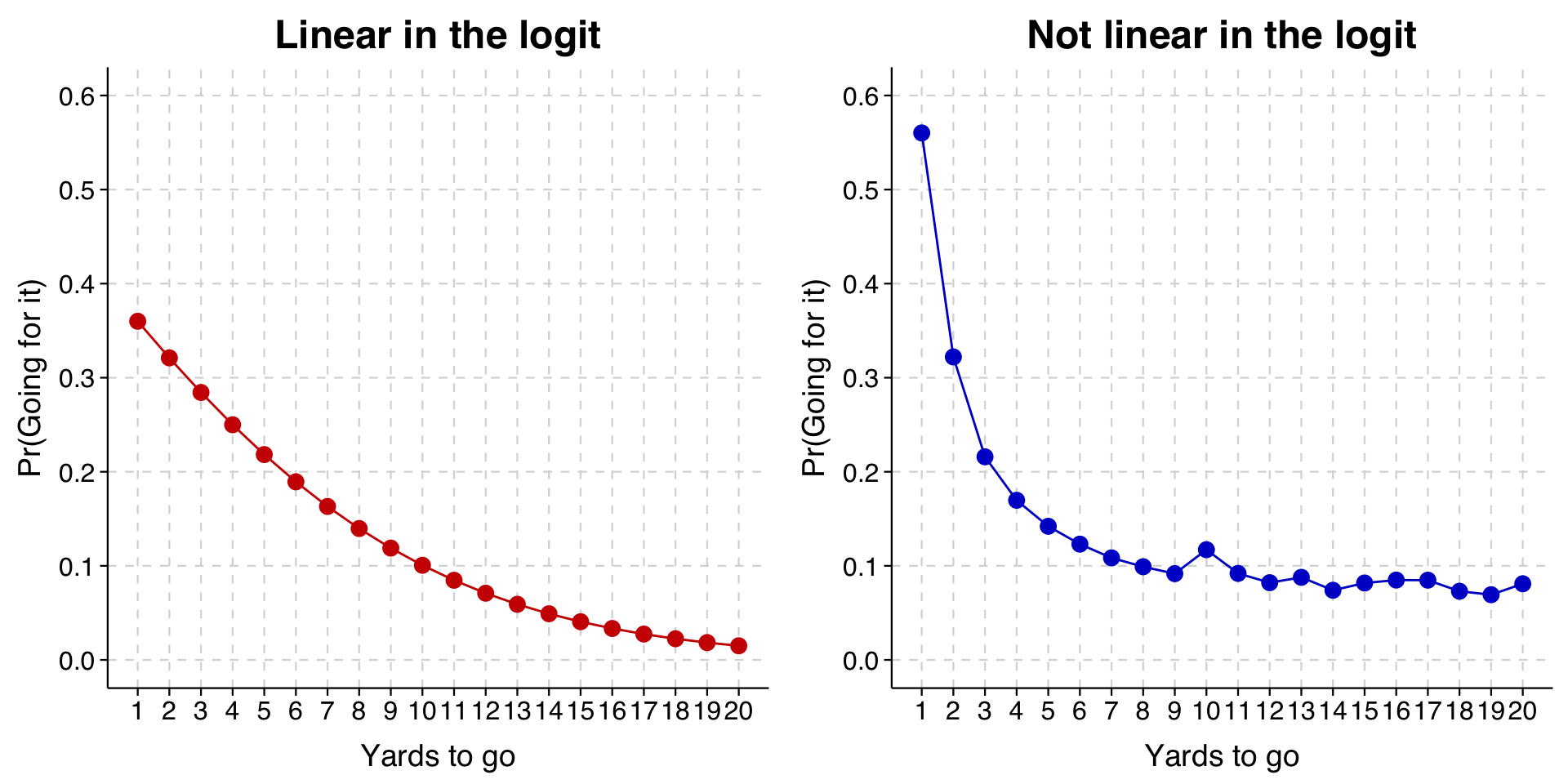
A different possibility is that we want to relax the assumption that the relationship between yards-needed and fourth-down-decisions is linear in the logit. Given that yards needed is measured as an integer, the most flexible way to do this is to treat it like it was a categorical variable in our model, so that there is a different coefficient for every distance value.
We will also recode values of yds_needed that are larger than 20 to 20 so that we don’t have any problems with too few cases.
In the output above, you can see that there is now a separate parameter for each value of \(\mathtt{yds\_needed}\), with 1 used as the base category. Recall that we earlier recoded values higher than 20 to equal 20.
We will draw this graph alongside the graph we drew at the beginning to make the difference clearer.
Expand to show code that draws comparison plot
toplot_linear <-avg_predictions(model,variables =list("yds_needed"=seq(1, 20, 1)))toplot_factor <-avg_predictions(model4,variables =list("yds_needed_max20"=seq(1, 20, 1)))p1 <-ggplot(toplot_linear, aes(x = yds_needed, y = estimate)) +geom_line(color ="red3") +geom_point(color ="red3", size =3, shape =21, fill ="red3") +scale_y_continuous(limits =c(0, 0.6), breaks =seq(0, .6, .1)) +scale_x_continuous(limits =c(1, 20),breaks =seq(1, 20, 1),minor_breaks =NULL) +labs(x ="Yards to go",y ="Pr(Going for it)",title ="Linear in the logit" ) +theme_tula() +theme(plot.title =element_text(hjust =0.5))p2 <-ggplot(toplot_factor, aes(x = yds_needed_max20, y = estimate)) +geom_line(color ="blue3") +geom_point(color ="blue3", size =3, shape =21, fill ="blue3") +scale_y_continuous(limits =c(0, 0.6), breaks =seq(0, .6, .1)) +scale_x_continuous(limits =c(1, 20),breaks =seq(1, 20, 1),minor_breaks =NULL) +labs(x ="Yards to go",y ="Pr(Going for it)",title ="Not linear in the logit" ) +theme_tula() +theme(plot.title =element_text(hjust =0.5))grid.arrange(p1, p2, ncol =2)
The new model is on the right. As you can see, when the model is no longer constrained to the logit curve, the probability of going for it on fourth-and-1 is higher than what was fit before, as is the probability of going for it on fourth-and-long.
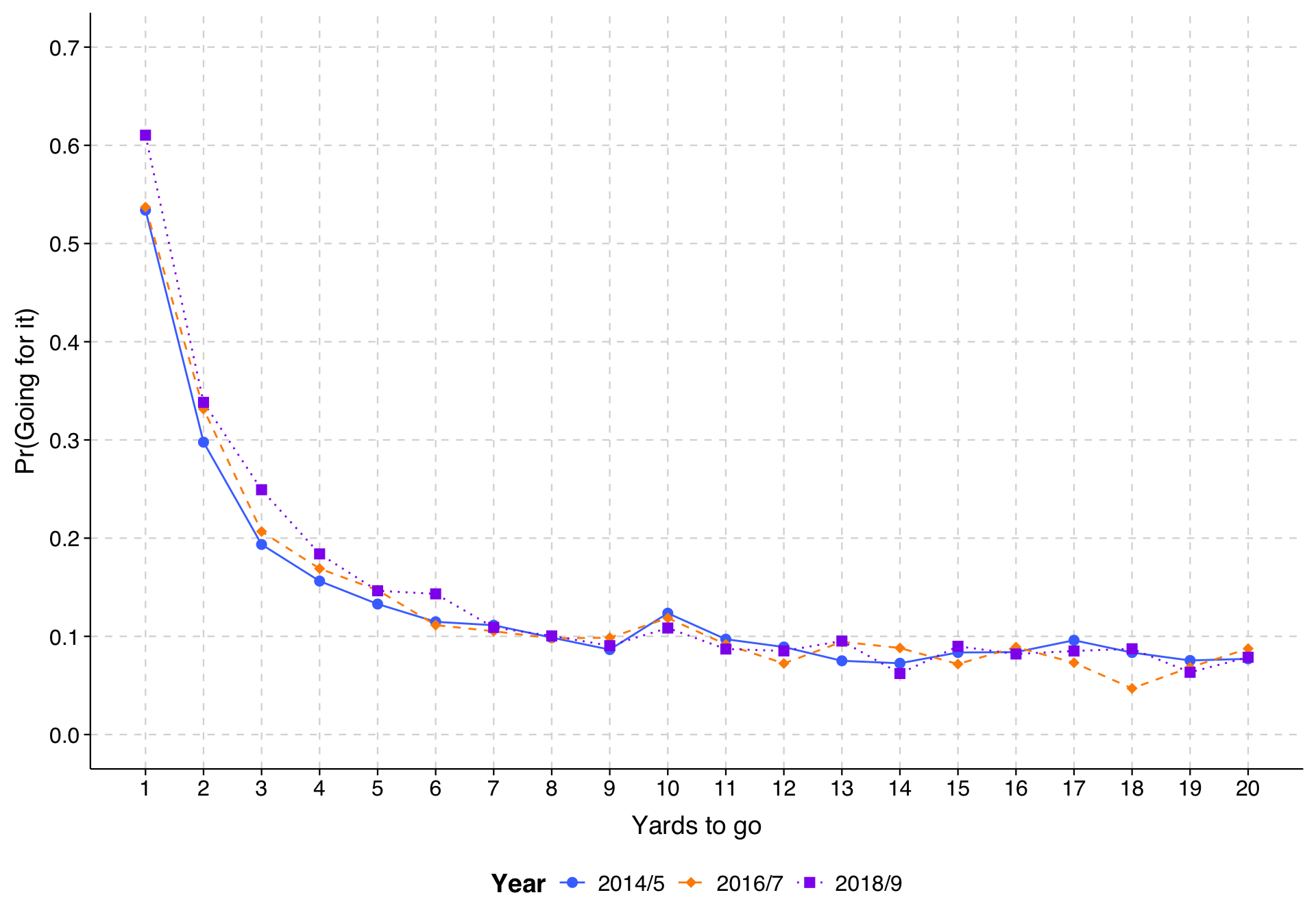
Last, we can combine both approaches, and include interaction terms and model each value of yds_needed and year as a separate coefficient to have the most flexible specification. (We lump years into two-year groups so that we don’t have any small combinations of yds_needed and our recoded year variable.)
Expand to show code that fits model and draws plot
From this, we can see that the tendency for teams to go for it more in recent years appears to have emerged particularly in 2018/9 and particularly in the very short yardage situations. Once a team gets past 4th-and-7 or so, yardage doesn’t make much difference for whether teams decide to go for it (presumably because the main reason they do is when they are behind at the end of the game and have to), and there hasn’t been any change over time.
Important: Prediction plots can only show patterns as complex as the model that has been fit. The simplicity of a pattern in a plot may belie the actual pattern underneath. Of course, you might then wonder why people do not just jump immediately to the most complicated model. If one has a continuous explanatory variable, for example, why not always just break the data into as fine a set of dummy variables as possible and use that?
The answer is that the approach has its own problems, namely that as the size of the dummy-variable-categories gets smaller, the more the predicted probabilities are influenced by chance variation. In other words, the resulting plots are more jagged than they would be if our sample sizes were larger, and that provides a distorted picture of reality as well.