The cumulative hazard
We can introduce different parametric survival models in terms of the hazard function. For example, we will soon talk about the simplest parametric model, exponential regression, and the hazard function for that will just be:
\[ h(t|\mathbf{x}_i) = \exp(\mathbf{x}_i\mathbf{\beta}) \]
Given a hazard function, we will also want to be able to work out how the implied probability of survival changes over time–that is, the survivor function. For that, a useful intermediate concept will be the cumulative hazard.
The cumulative hazard is the expected number of times would occur if the event could happen repeatedly.
In usual survival data, the occurrence of the failure event represents the “end” of the observation. But this need not be the case. In our toy example of an individual buying tickets in California’s Daily 3 lottery, for example, a person who buys a lottery ticket every day can keep on buying after they win the first time, and we could keep track of how many times they are winning.
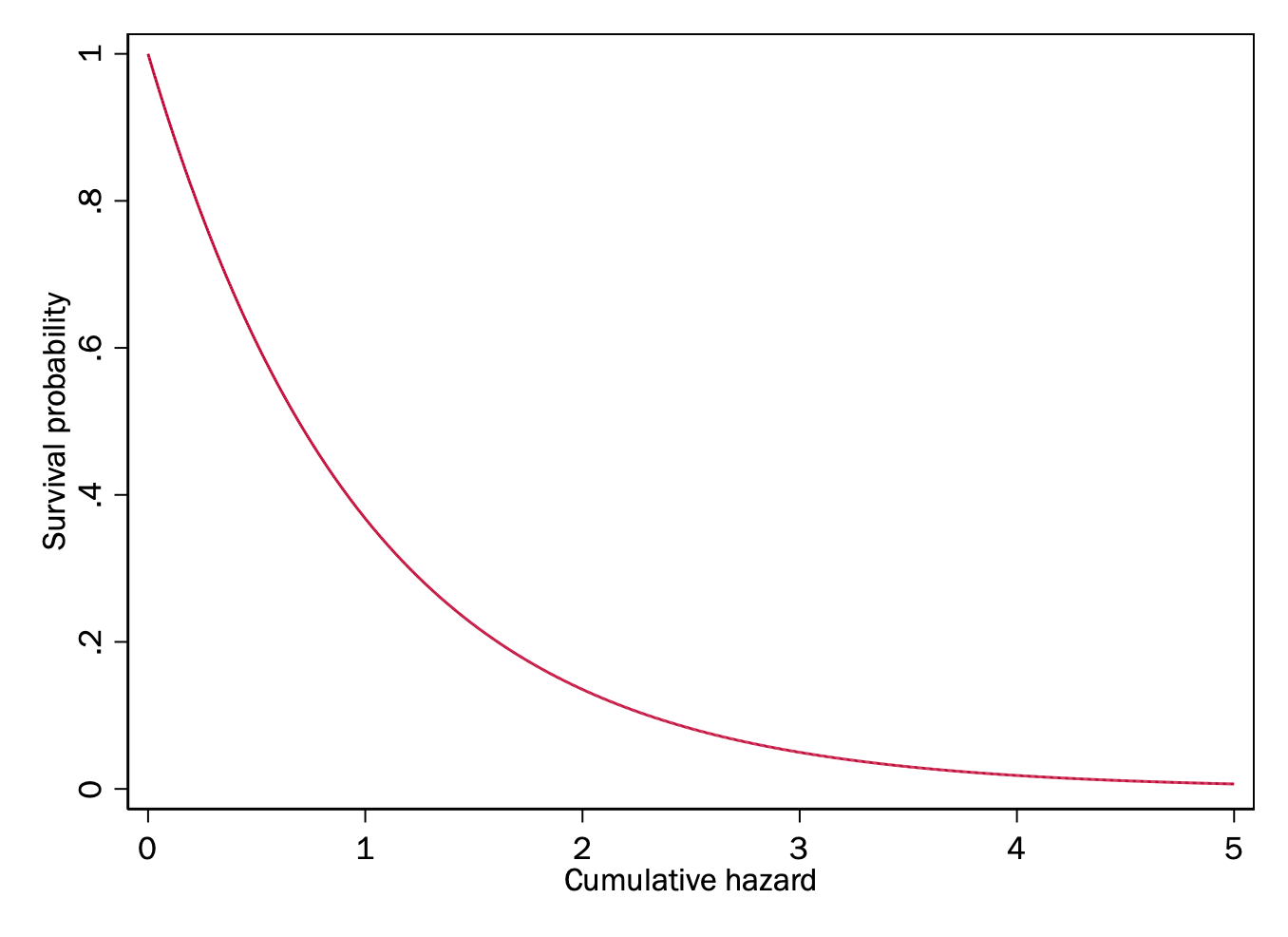
For an outcome like death that in fact only happens once (barring resurrection or zombies), the cumulative hazard is more of a useful fiction. The reason it is useful is that it has a relationship to the survivor function: that is, the probability of the event having happened to someone for the first (or only) time, and we do care about the survivor function. Specifically, given the cumulative hazard \(H(t)\) – note the capital \(H\) – , the survivor function is:
\[ S(t) = \exp(-H(t)) \]
This relationship between the survivor function and the cumulative hazard makes sense because:
- At \(t = 0\), the cumulative hazard is 0, which makes \(S(t) = 1\).
- After that, the cumulative hazard \(H(t)\) is always positive, which means that \(-H(t)\) is always negative. Since the exponent of a negative number is always between 0 and 1, that \(-H(t)\) is negative means that \(\exp(-H(t))\) is between 0 and 1.
- As \(H(t)\) increases, \(S(t)\) decreases.
- As \(H(t)\) increases, each additional unit increase in \(H(t)\) yields a smaller and smaller decrease in \(S(t)\).
Aside: Connection to count outcomes. The cumulative hazard is what will link the study of event outcomes to the study of count outcomes. Many count outcomes can be thought of the number of occurrences of an event that can happen repeatedly, and if so then the expected count and the cumulative hazard are the same thing.
Key points
- The cumulative hazard is the expected number of times an event would occur for an observation if the event could happen repeatedly.
- The cumulative hazard is conventionally written as \(H(t)\), whereas the hazard itself is \(h(t)\).
- The cumulative hazard is a useful notion even if substantively the event cannot happen repeatedly. The reason it is useful is that the way we get from a hazard function \(h(t)\) to a survivor function \(S(t)\) is that a hazard function implies a cumulative hazard function, and the survivor function is \(S = exp(-H(t))\).