<– This should be expanded or another handout to include robust poisson –>
We have discussed how the Poisson distribution follows from a specific sort of data generating process: one in which events occur independently and at a specific and constant rate, indicated by \(\lambda\), over all observations. When instead the rate \(\lambda\) varies over observations, the data will no longer follow a Poisson distribution, but instead it will have greater variance.
The premise of Poisson regression is that the data are conditionally distributed as Poisson. In other words, for observations that share the same values of \(\mathbf{x}\), the data are distributed as Poisson.
The data as a whole, on the other hand, will have a higher variance than expected under Poisson, which means the data as a whole will not be Poisson distributed.
The Poisson regression model
In the Poisson regression model, our outcome is the log of the rate \(\lambda\):
\[
\ln(\lambda) = \mathbf{x}\mathbf{\beta}
\]
Consequently, when we exponentiate both sides of the equation, \(\exp(\mathbf{x}\mathbf{\beta})\) provides our estimate of \(\lambda\) given \(\mathbf{x}\).
And, taking the formula provided earlier for the Poisson distribution, we can calculate the predicted probability of any given count for the \(\lambda\) implied by the value of \(\mathbf{x}\) and our coefficients for any observation:
We use the predicted probabilities of the observed values to fit the model using maximum likelihood. That is, for each observation, the likelihood is the predicted probability of the observed count.
Toy example
We will use a simulated data example, modeled after our discussion of the Prussian horse-kick data. The reason we are using simulated instead of real data is that, with a simulation, we control the data generating process and so we know that the answer ought to be given how we simulate the data. Another advantage is that by simulating data we know the data does not violate an important assumption of Poisson regression that we will discuss shortly.
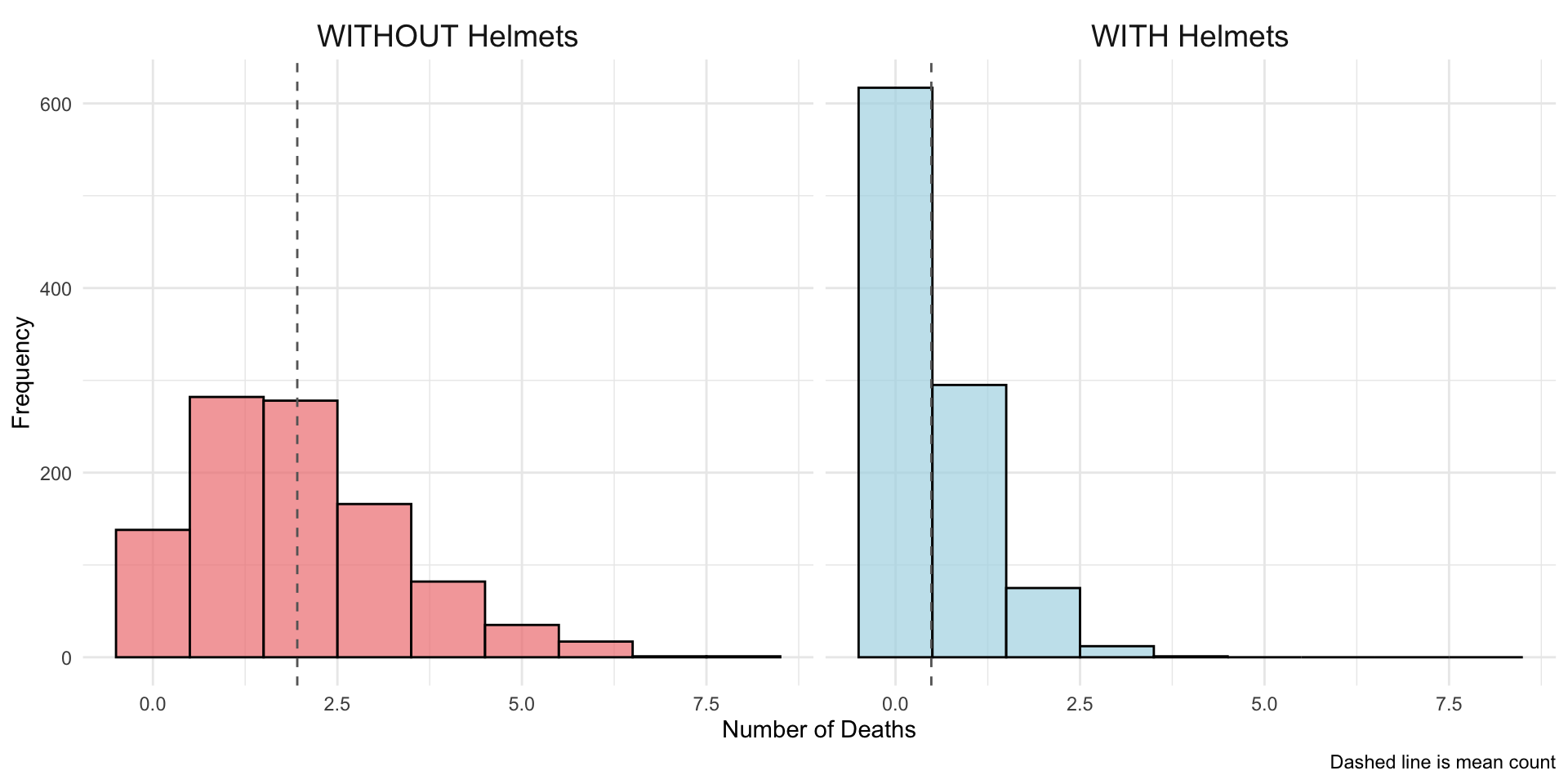
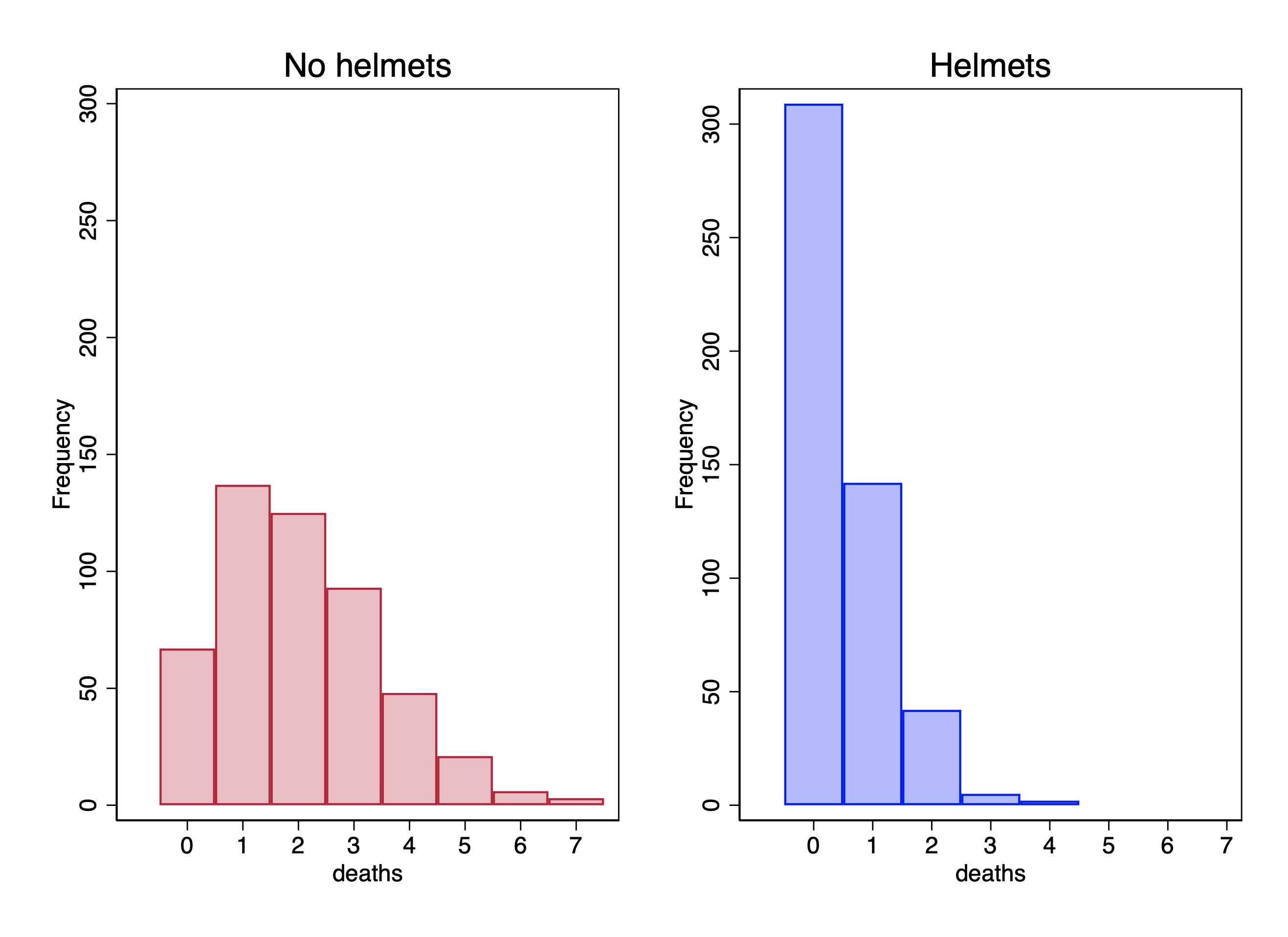
To motivate our simulation, say that death-by-horsekick was a random event, but that some units wear helmets and that this lowers the risk of dying. The expected mean mortality rate for units without helmets is 2 deaths per unit, but with helmets this decreases to .5. Helmets, thus, decrease the mortality rate by 75%.
We have 500 units with helmets and 500 units without helmets. Here’s a cross-tab of our simulated data:
We obtain a coefficient of -1.39. The sign of the coefficient shows us that the mortality rate is lower for the units that wear helmets.
The magnitude of the coefficient is an additive difference in the log-rate. As with other models we have considered with a logged outcome, we make the coefficient more interpretable by exponentiating it:
exp(coef(model))
(Intercept) helmetsTRUE
1.9020000 0.2597266
The exponentiated coefficient is .25. This corresponds to what we simulated: the mortality rate for units that wear helmets is .25 the size of the mortality rate for units without helmets; that is, the mortality rate for units that wear helmets is 75% less.
The negative sign of the coefficient indicates that helmets decrease the rate of deaths. However, for interpretation, we would likely want to exponentiate this coefficient.
\[
\exp(-1.41) = .244
\]
This is the factor change in the rate. Remember that we simulated these data so that we know the rates are approximately .5 for the corps with helmets and 2 for the corps without. So indeed, the mortality rate for the corps with helmets is only about 25% as much as the mortality rate for corps without helmets, because .5 is about 25% as much as 2.
We could interpret the result in terms of the percentage decrease:
The mortality rate for units with helmets is about 75% lower than the mortality rate for units without helmets.
where the 75% comes from (1 - .244).
Austin animal shelter example
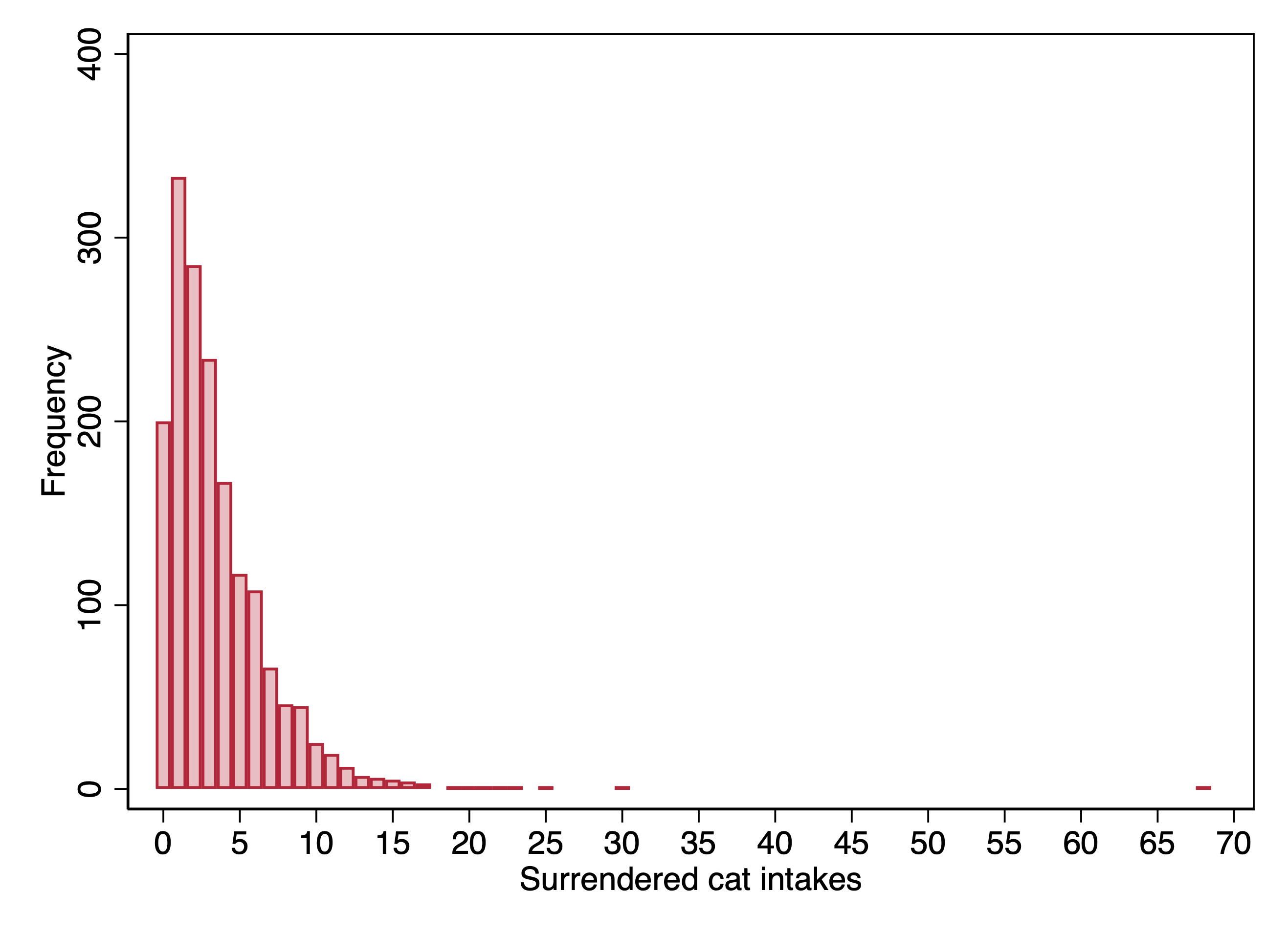
The dataset \(\texttt{austin\_animals\_dailycounts}\) includes daily data on the number of animals of different types arriving at the shelter. We will look at the outcome of the number of cats surrendered on a day. We can look at a histogram of this outcome:
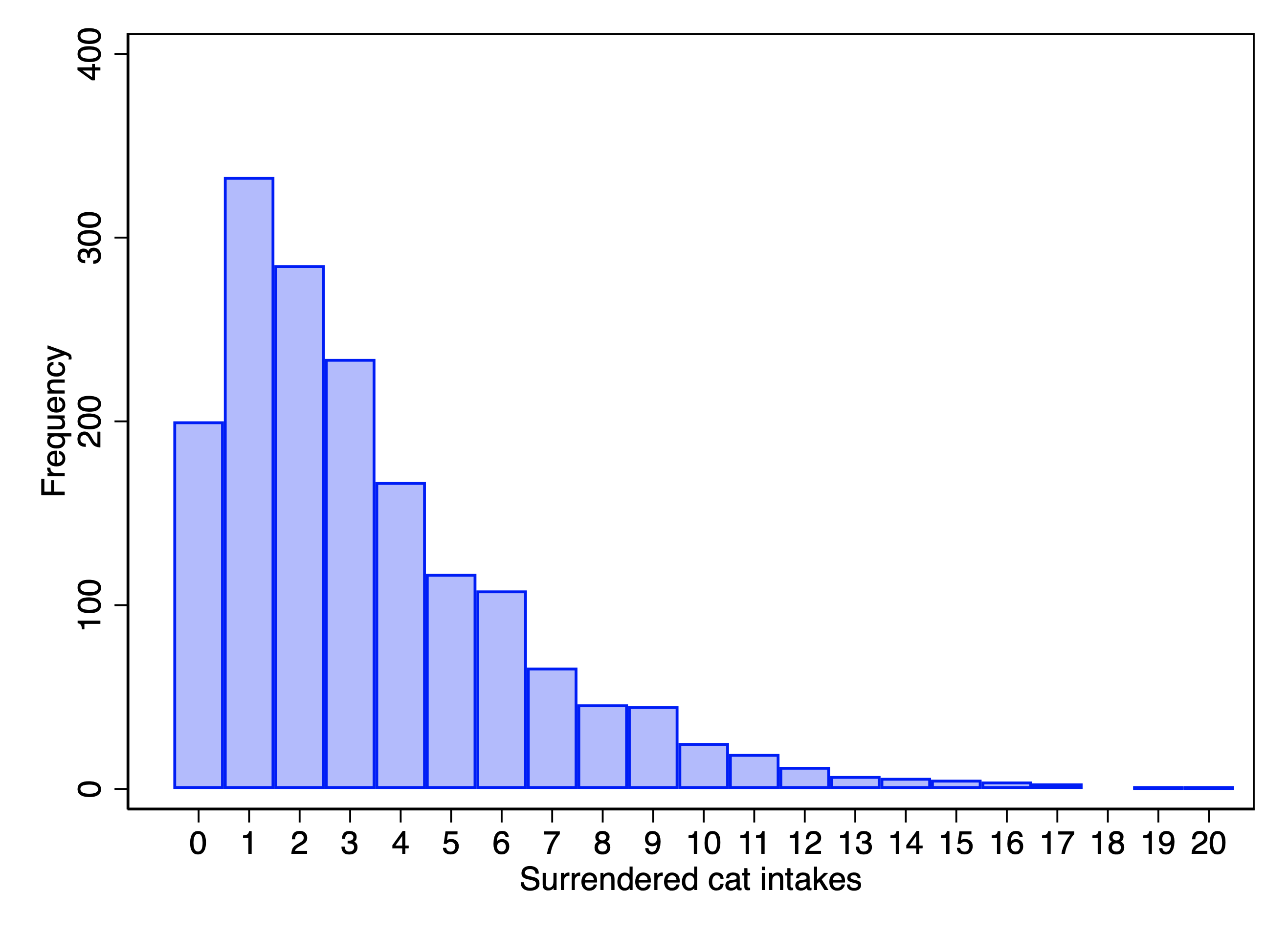
Given that this is real data, we run into an issue where we have some outliers. Given that the median number of cats per day is 3, it seems obviously not just a matter of random chance that we have a day when 68 cats were surrendered. Instead, one suspects that some of these extreme days reflect a cat hoarder who was probably compelled to give up their cats (or died). Because these seem like fluke events that I don’t want to overwhelm the overall pattern in the data, I am going to make the executive decision and recode any counts of greater than 20 to 20.
In the Stata version, I cut counts greater than 20, rather than recode to 20. Recoding in retrospect seems like the better approach and so have as a to-do to recode the Stata data accordingly. As a result, the Stata and R results presently do not quite match.
We will model this in terms of the month and day of week of the date.
After fitting the model in R, I re-fit it so that the categories with the lowest coefficients were the base categories (which turn out to be February and Sunday).
In fitting the Poisson model in Stata, I use the \(\texttt{irr}\) option so as to automatically get exponentiated coefficients (incidence rate ratios), and I re-fit the model so that the categories with the lowest coefficients were the base categories (which turn out to be March and Sunday).
To obtain this in R for specific values we can use the marginaleffects package. For example, we can compare Thursdays in February to Thursdays in September.
The predicted number of surrendered cats for a Thursday in February is 2.79, while for a Thursday in September it is 4.34, for a difference of 1.55. In percentage terms, the difference between September and February is \(\frac{1.55}{2.79} = .55\). This corresponds to our above interpretation that the predicted number of surrendered cats is 55% more for days in September than it is for the same day of the week in February.
Let’s compare the predictions for a Thursday (\(\texttt{day_of_week==4}\)) in September vs. a Thursday in March.
The predicted number of surrendered cats for a Thursday in March is 2.78, while for a Thursday in September it is 4.28, for a difference of 1.50. In percentage terms, the difference between September and March is \(\frac{1.50}{2.78} = .540\). This corresponds to our above interpretation that the predicted number of surrendered cats is 54% more for days in September than it is for the same day of the week in March.
TODO: Compute predictions for individual counts (not available in marginaleffects).
Testing fit of Poisson model
After fitting a Poisson regression model, we can check to see if the data were indeed conditionally Poisson.
There are two different tests of note. The null hypothesis for both tests is that the data are consistent with the expectations of the conditional Poisson distribution.
In our example, both tests resoundingly reject the null hypothesis that the data are distributed as Poisson. In other words, even after taking month and day of week into account, the data still have more variance than we would expect if the data generating process was conditionally Poisson.
A term for this is overdispersion: the counts are too dispersed. This is very common with data when the counts are events.